Next: HST/ACS Associations: the Next Step after WFPC2
Up: Surveys &
Large Scale Data Management
Previous: The INTEGRAL Archive System
Table of Contents -
Subject Index -
Author Index -
Search -
PS reprint -
PDF reprint
Ochsenbein, F., Derriere, S., Nicaisse, S., & Schaaff, A. 2003, in ASP Conf. Ser., Vol. 314 Astronomical Data
Analysis Software and Systems XIII, eds. F. Ochsenbein, M. Allen, & D. Egret (San Francisco: ASP), 58
Clustering the large VizieR catalogues, the CoCat experience
François Ochsenbein, Sébastien Derriere,
Sébastien Nicaisse, André Schaaff
Centre de Données astronomiques de Strasbourg (CDS),
Observatoire de Strasbourg, UMR 7550,
11 rue de l'Université, 67000 Strasbourg, France
Abstract:
VizieR is a database containing about 4000 astronomical catalogues with
homogeneous descriptions. The major part of the catalogues is stored in a
relational database but the large catalogues containing over 10 millions rows are
stored as compressed binary files and have dedicated query
programs for very fast
access by celestial coordinates.
The CoCat (Co-processor Catalogue) project main goal is
to parallelize the VizieR large catalogue treatments (data extraction,
cross-matching) for reducing the response time.
The VizieR catalogue service
(Ochsenbein et al., 2000)
is currently implemented on a Sun 4-processor server.
In the recent years the competitivity of PCs dramatically increased,
with very high performances and ever decreasing costs,
and in many circumstances, clusters
of Linux PCs are replacing the big standalone servers.
In the VizieR case, the current load is high
and it was urgent to choose between a complete replacement or an
additional server.
VizieR catalogues are divided into two categories: standard and
large catalogues, where
large catalogues are defined, somewhat arbitrarily, as
having more than 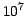 rows. Catalogues with up to a
few million records are managed by a standard relational DBMS, while
each of the larger catalogs has a dedicated
query program which retrieves the records corresponding
to a some circular or rectangular region around a position in the sky.
Some details about the methods used to store the large catalogues
and their performances, in terms of speed and disk usage,
are given in Derriere et al. (2000);
the current list of these large catalogues is given in Fig.1.
It should be noted that both ``standard'' and ``large'' catalogues
share the same metadata descriptions -- the VizieR interface simply
translates the user's requests either into SQL queries, or into
some customized set of parameters interpretated by the dedicated query program.
rows. Catalogues with up to a
few million records are managed by a standard relational DBMS, while
each of the larger catalogs has a dedicated
query program which retrieves the records corresponding
to a some circular or rectangular region around a position in the sky.
Some details about the methods used to store the large catalogues
and their performances, in terms of speed and disk usage,
are given in Derriere et al. (2000);
the current list of these large catalogues is given in Fig.1.
It should be noted that both ``standard'' and ``large'' catalogues
share the same metadata descriptions -- the VizieR interface simply
translates the user's requests either into SQL queries, or into
some customized set of parameters interpretated by the dedicated query program.
Figure 1:
The large catalogues in the cluster
(version October 2003)
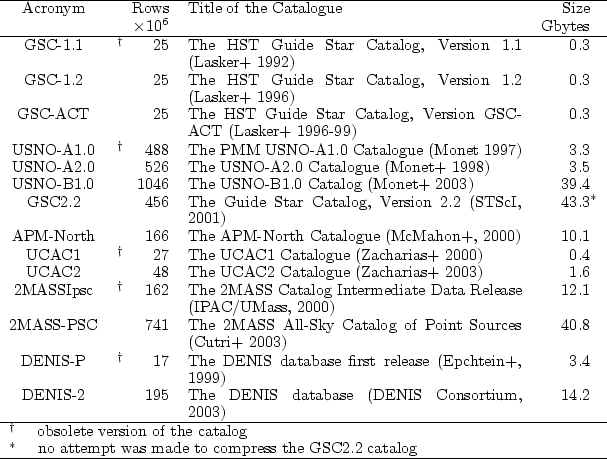 |
Figure 2:
The CoCat cluster.
 |
As the Sun server is becoming overloaded we decided to
move the set of large catalogues to a Linux cluster
(the CoCat cluster).
It then becomes easy to increase the computing power or
the storage capability at a very low cost; it represents also a flexible solution for the future evolutions.
A wide range of free or commercial clustering tools is available.
We started with a new free clustering tool package,
CLIC
(Cluster LInux
pour le Calcul) which makes use of the MPI library
(Message Passing Interface)
and is based on the Mandrake Linux 9.0 distribution.
The CoCat
cluster involves one master node and five slave nodes (Fig 2).
Tools like MPI are designed to run parallelized CPU-intensive tasks
on a cluster, but in
the CoCat case it is necessary to dispatch a large number of
queries (typically 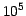 -
-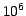 daily requests) and their results.
The large catalogues being stored in a compact form, it was possible
in a first step to replicate the data (about 200Gbytes) on each node.
With the increasing number of increasingly larger catalogues
it will be necessary in the near future to distribute the data
over several nodes, and it will become mandatory to describe
on which engines which part of which catalogue can be accessed:
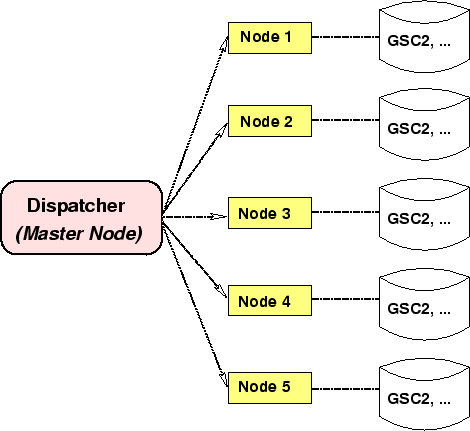
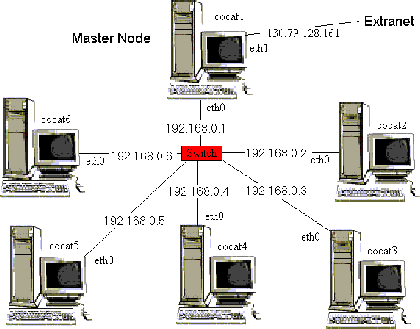
this role is devoted to the Dispatcher, running on the master
node, and illustrated in Fig. 3.
daily requests) and their results.
The large catalogues being stored in a compact form, it was possible
in a first step to replicate the data (about 200Gbytes) on each node.
With the increasing number of increasingly larger catalogues
it will be necessary in the near future to distribute the data
over several nodes, and it will become mandatory to describe
on which engines which part of which catalogue can be accessed:
this role is devoted to the Dispatcher, running on the master
node, and illustrated in Fig. 3.
Figure 3:
CoCat global architecture
 |
The first tests showed that the performances are not as high
as expected: the overhead of the MPI library is large compared
to the time required by the actual execution of the
requests initiated by the Dispatcher.
The CLIC package, while easing up the installation of the system
and the applications on the cluster nodes, requires
an identical hardware configuration of each node: this introduces
a severe lack of flexibility in the management and the evolution of the cluster.
We are currently testing new configurations for
a more performant Dispatcher, where each node is considered
as an independent resource and where the Dispatcher assigns the tasks
according to its knowledge of the current load on each node.
Such a method seems to work well in the current situation where
all catalogues are present on each node, but in a
near future we will have to
take some important decisions about:
- which strategy to adopt about splitting
the very large catalogues and how to distribute catalogue subsets
on the different cluster nodes
- whether it would be useful to dedicate one or several nodes
to specific tasks (e.g. cross-matching)
- whether it would still be useful to implement a parallel processing
(e.g. for cross-matching large catalogues) in the dispatcher.
References
Derriere, S., Ochsenbein, F., & Egret, D.
2000, in ASP Conf. Ser., Vol. 216,
Astronomical Data Analysis Software and Systems
IX, ed. N. Manset,
C. Veillet, & D. Crabtree (San Francisco: ASP), 235
Ochsenbein, F., Bauer, P., & Marcout, J. 2000, A&AS, 143, 23
© Copyright 2004 Astronomical Society of the Pacific, 390 Ashton Avenue, San Francisco, California 94112, USA
Next: HST/ACS Associations: the Next Step after WFPC2
Up: Surveys &
Large Scale Data Management
Previous: The INTEGRAL Archive System
Table of Contents -
Subject Index -
Author Index -
Search -
PS reprint -
PDF reprint